
מקצה לקצה: תכנון נכון של פרויקטים בתחומי AI / HPC
לא מדברים על GPU בלבד, אלא בעיקר על אומנות אינטגרציה לאקו-סיסטם שלם

בשנים האחרונות התשתיות והטכנולוגיות בתחום ה Artificial Intelligence (AI בהמשך) הולכים ומגיעים לבשלות. אנו בבינת, כחברת אינטגרציה מהמובילות והוותיקות בארץ, רואים את התהליכים האלה לובשים צורה וקורמים עור וגידים בפרויקטים רבים. במקביל, תשתיות HPC (High Performance Computing) מסורתיות הולכות ומוכוונות יותר לתמוך בתחומי ה AI. נכון להיום רוב החברות נמצאות בתהליכים להכנסת יכולות AI בתשתיות שלהם, בין אם זה במוצרים או בשירותים העסקיים שמשרתים את לקוחותיהם.
לאחר תכנון וביצוע של פרויקטים בתחומי AI / HPC מהגדולים בארץ, אנו יודעים לומר שהצלחת קפיצת המדרגה הטכנולוגית המצופה מהפרויקט תלויה במידה רבה באינטגרטור מיומן בנושא. מורכבות האינטגרציה והחשיבות של היכולת להביא בחשבון את כלל ה Eco-system בפרויקטים מסוג זה דורשים מבט רחב היקף והוליסטי על כלל הסביבה. על מנת להבין מה עומד מאחורי הקביעה הזו חשוב להבין את הרקע למערכות ה AI במבט תשתיתי.
ביצוע אנליטיקה ו AI דורשים איסוף ועיבוד כמויות גדולות ומגוונות של Data. ה- GPU (להבדיל מה CPU) הפך לכלי העיבוד המרכזי במערכות אלה בעיקר בגלל היכולת לטפל ביעילות בתהליכים מתמטיים מורכבים, ריבוי ליבות עצום בעלות נמוכה יחסית וארכיטקטורת עיבוד פרללית. חשוב להבין שהיכולת לנצל את מלוא הפוטנציאל של כרטיסי GPU תלויה בקצב ההזנה של הנתונים אליהם. מאחר ולרוב מדובר על מספר כרטיסים העובדים במקביל ולעיתים גם במערכות Multi-node שכל אחד מהם בתצורת Multi-GPU, נדרש קצב גבוה מאוד של הזנת נתונים דבר המשפיע על כלל התשתיות במערכת. תשתיות האחסון והתקשורת נדרשות לא רק לספק את הנפח הנדרש אלא גם את הביצועים וזמני התגובה הנמוכים לניצול יעיל של המערכת.
אינטגרציה נכונה של שלושת המרכיבים – עיבוד, אחסון ותקשורת – הינה קריטית והיא זו שתאפשר לנו להתמקד בתזמור נכון ויעיל של שכבת היישומים ב Cluster.
נקודה משמעותית נוספת הדורשת התייחסות היא שבמערכות AI שכבת התוכנה מבוססת כולה על מערכות קוד פתוח. בין היתר: Docker / Kubernetes, Operating System Optimized לתמיכה ב Orchestrator, Workloads כדי לתזמן את כלל הפעולות ביעילות בין הרכיבים ומערך ניטור ואנליטיקה המאפשר מבט על הרכיבים השונים בתשתית על מנת לנצל אותם בצורה אופטימלית.
הרכיבים לתפקוד אופטימלי
בפרויקט שבינת תכננה לאחרונה באו לידי ביטוי הנקודות שדנו בהם עד כה. מטרת הפרויקט הייתה הקמת Cluster ארגוני מוכוון HPC ו-AI עבור המפתחים. נדרשה רמת אינטגרציה גבוהה בפרויקט לתכלול הרכיבים המאפשרים למערכות לתפקד באופן אופטימאלי. להלן סקירה קצרה:
תשתית השרתים בפרויקט מבוססת מערכות Apollo 6500 של חברת HPE עם כרטיסי GPU מסוג NVidia A100 לאימון המודלים וכרטיסי A30 NVidia עבור Inferencing. מבנה השרתים מבטיח גמישות מרבית בכמות וסוג כרטיסי ה GPU וכוללים שכבת דיסקים מהירים במיוחד מבוססים טכנולוגיית NVME לצורך Caching מקומי.
מערך האחסון המרכזי הותאם ספציפית לסביבות HPC / AI וכלל שכבת נפח עבור ה Data Lake לנתונים הגולמיים המתבטא בדרך כלל בנפחים גבוהים של PB's ושכבת נפח עבור ה Data sets לאימונים וה Inferencing המאופיינת בגישה המהירה הנדרשת להזנת הנתונים ליחידות ה GPU בקצב גבוה. שני אזורי האחסון מנוהלים כיחידה אחת תחת אותו Single namespace כאשר שירות הקבצים המקבילי מבטיח העברת הנתונים במהירות גבוהה משמעותית מהמקובל בשרותי קבצים מסורתיים.
ברמת התקשורת – תשתית Infiniband מקצה לקצה תוכננה על מנת להבטיח את היכולת לספק את הנתונים בקצב גבוה וברמות Latency נמוכות ליחידות ה GPU.
כמו כן הוקמה סביבה וירטואלית של VMware על מנת לתמוך ברכיבי הניהול של המערכת דוגמת: LDAP , SLURM , Kubernetes, OS Imaging לאוטומציה ואורקסטרציה של משאבים, RUN:AI להאצת ביצועים באמצעות אופטימיזציה והרצה מתוחכמת, ו Prometheus ו Grafana לניטור ואיסוף מטריקות של כל המערך.
חברת בינת שותפה עסקית בכירה של חברת HPE. הפורטפוליו הרחב של חברת HPE – הכולל גם את הפתרונות של חברת Cray שנרכשה לאחרונה – מאפשר לנו לתכנן ולבנות פתרון AI / HPC מקצה לקצה מבית אחד.
באזורי ה AI: ניתן למצוא החל מתשתיות האחסון ClusterStore בארכיטקטורת Scale-Out שמגישות את הנתונים באמצעות פרוטוקול Parallel File System עתיר ביצועים. שכבת רשת מהירה Slingshot לחיבור Low Latency בין הרכיבים, ושכבת שרתים מבוססים על משפחת Cray-Apollo המותאמות במיוחד לסביבות מרובות GPU לצורכי Training ו Inferencing.
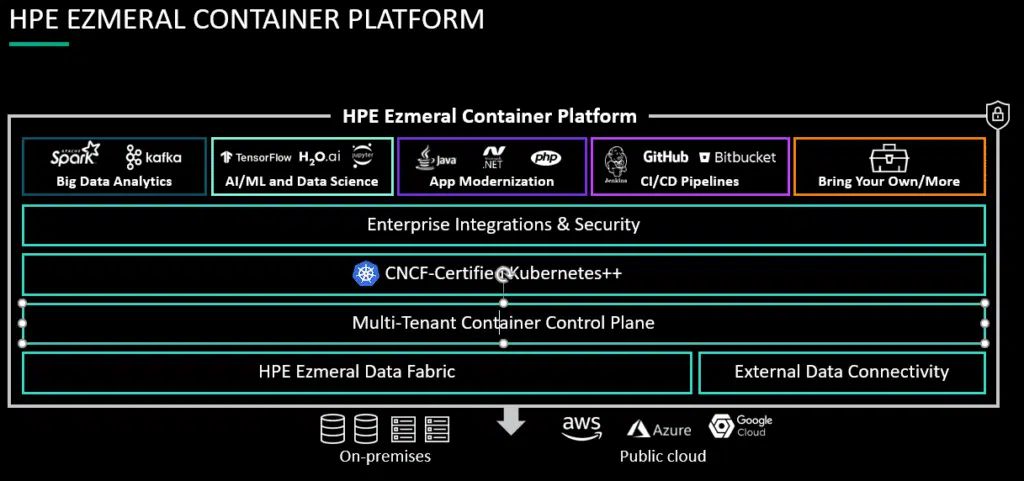
ללקוחות המעוניינים להשלים את אזור ה AI עם שכבת HPC לטיפול והכנה של סביבת הנתונים, ניתן להוסיף שכבת אחסון SDS Ezmeral Data-Fabric המציעה סביבת אחסון מודולארית, מולטי פרוטוקול ומולטי Cloud עם יכולת גדילה ל PB's', ושכבת Compute הכוללת שרתי ProLiant מבוססי Intel או AMD הכוללים תמיכה ב GPU ככוח עזר לתהליכים השונים.
ניהול שני האזורים הנ"ל מתבצע באמצעות שני מוצרים עיקריים:
- HPCM (High Performance cluster Manager) באזור ה HPC להקמה, ניהול, ניטור ותפעול של HPC Clusters
- ומערכת Ezmeral המהווה מעטפת הכוללת Data Fabric Management עם יכולות Multi-Cloud, ופלטפורמה להקמה וניהול של סביבות Containers כולל יכולות Multi-Tenant, סט של כלים זמינים ל Data-Ops, ML-Ops, כלים ל Code transformation ואינטגרציה עם סביבות CI/CD של המפתחים וכל זה עטוף ב Business Portal המצויד גם ב Marketplace עשיר הניתן להשלמה ביישומים נוספים בהתאם לצורך.
עבור קהילת ה-Data science, ה-Ezmeral גם מאפשר אינטגרציה מתקדמת עם הכלים הנדרשים סביב פלטפורמטת Jupyter.

חשוב לציין שאת כל זה ניתן לקבל גם במסגרת מודל עסקי Consumption-as-a-Service בשם GreenLake במסגרתו הלקוח משלם רק על מה שהוא צורך בפועל. המודל גמיש ומאפשר התאמה למערכות בגדלים שונים ומהווה יתרון משמעותי במקרים שלא ניתן לצפות מראש את גודל המערכת הנדרשת.
לסיכום, האתגר המרכזי במערכות AI/HPC כיום הוא באינטגרציה הנכונה של כל ה Ecosystem בכלל שכבות התשתית – חומרה ותכנה גם יחד. חברת בינת יודעת לספק ליווי מקצועי בכלל הדרישות של פרויקט מסוג זה: החל מאינטגרציה ואוטומציה של התשתיות ושילובם במערכת הארגונית, צוות מומחים המספקים DevOps services עבור אינטגרציה של סביבת הפיתוח של הלקוח אל פרויקט ה AI/HPC וצוות ייעודי הכולל מפתחים בתחום ו Data Scientists ופיתוח של מודלים AI, כולל Data Modeling ואלגוריתמיקה מתקדמת בתפיסת Turn-key.







 הדור הבא של המולטימדיה הארגונית: חוויות מבקר, חדרים חכמים ו־ AI בזמן אמת
הדור הבא של המולטימדיה הארגונית: חוויות מבקר, חדרים חכמים ו־ AI בזמן אמת
 חדשנות מבוססת AI כנקודת מפנה טכנולוגית ואסטרטגית
חדשנות מבוססת AI כנקודת מפנה טכנולוגית ואסטרטגית
 חמישים גוונים של דאטה ואתגרים ל- AI ארגוני
חמישים גוונים של דאטה ואתגרים ל- AI ארגוני
 ריבונות נתונים ובינה מלאכותית: התפיסה החדשה של חוסן ארגוני במצבי קיצון
ריבונות נתונים ובינה מלאכותית: התפיסה החדשה של חוסן ארגוני במצבי קיצון
 כך תהפכו את ה-AI שלכם לגאון ב-5 שלבים בלבד
כך תהפכו את ה-AI שלכם לגאון ב-5 שלבים בלבד
 AI 360: שכבת הבינה החדשה של הממשלה
AI 360: שכבת הבינה החדשה של הממשלה